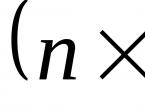Метод главных компонент заключается в том что. Метод главных компонент. Аппроксимация данных линейными многообразиями
Исходной для анализа является матрица данных
размерности
 ,
i-я строка которой характеризует i-е
наблюдение (объект) по всем k показателям
,
i-я строка которой характеризует i-е
наблюдение (объект) по всем k показателям .
Исходные данные нормируются, для чего
вычисляются средние значения показателей
.
Исходные данные нормируются, для чего
вычисляются средние значения показателей ,
а также значения стандартных отклонений
,
а также значения стандартных отклонений .
Тогда матрица нормированных значений
.
Тогда матрица нормированных значений

с
элементами

Рассчитывается матрица парных коэффициентов корреляции:

На
главной диагонали матрицы расположены
единичные элементы
 .
.
Модель компонентного анализа строится путем представления исходных нормированных данных в виде линейной комбинации главных компонент:

где
 -
«вес», т.е. факторная нагрузка
-
«вес», т.е. факторная нагрузка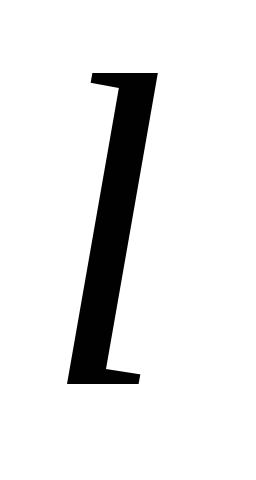 -й
главной компоненты на
-й
главной компоненты на -ю
переменную;
-ю
переменную;
 -значение
-значение
 -й
главной компоненты для
-й
главной компоненты для -го
наблюдения (объекта), где
-го
наблюдения (объекта), где .
.
В матричной форме модель имеет вид

здесь
 - матрица главных компонент размерности
- матрица главных компонент размерности ,
,
 -
матрица факторных нагрузок той же
размерности.
-
матрица факторных нагрузок той же
размерности.
Матрица
 описывает
описывает наблюдений в пространстве
наблюдений в пространстве главных компонент. При этом элементы
матрицы
главных компонент. При этом элементы
матрицы нормированы, a главные компоненты не
коррелированы между собой. Из этого
следует, что
нормированы, a главные компоненты не
коррелированы между собой. Из этого
следует, что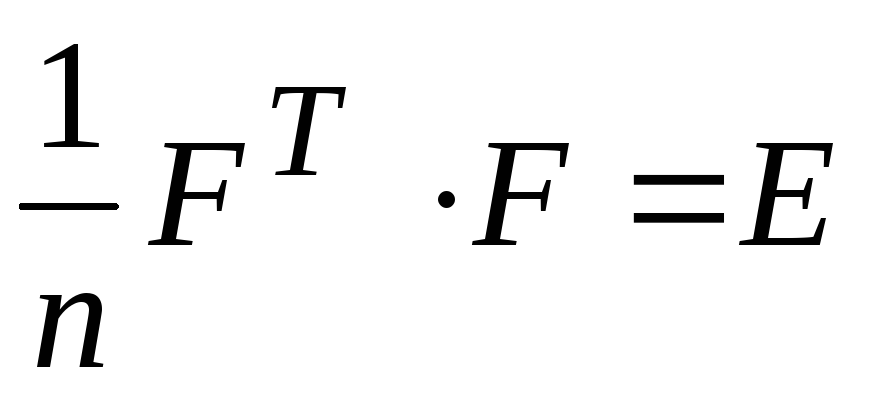 ,
где
,
где – единичная матрица размерности
– единичная матрица размерности .
.
Элемент
 матрицы
матрицы характеризует тесноту линейной связи
между исходной переменной
характеризует тесноту линейной связи
между исходной переменной и главной компонентой
и главной компонентой ,
следовательно, принимает значения
,
следовательно, принимает значения .
.
Корреляционная
матрица
 может быть выражена через матрицу
факторных нагрузок
может быть выражена через матрицу
факторных нагрузок .
.
По
главной диагонали корреляционной
матрицы располагаются единицы и по
аналогии с ковариационной матрицей они
представляют собой дисперсии используемых
 -признаков,
но в отличие от последней, вследствие
нормировки, эти дисперсии равны 1.
Суммарная дисперсия всей системы
-признаков,
но в отличие от последней, вследствие
нормировки, эти дисперсии равны 1.
Суммарная дисперсия всей системы -признаков
в выборочной совокупности объема
-признаков
в выборочной совокупности объема равна сумме этих единиц, т.е. равна следу
корреляционной матрицы
равна сумме этих единиц, т.е. равна следу
корреляционной матрицы .
.
Корреляционная матриц может быть преобразована в диагональную, то есть матрицу, все значения которой, кроме диагональных, равны нулю:
 ,
,
где
 - диагональная матрица, на главной
диагонали которой находятся собственные
числа
- диагональная матрица, на главной
диагонали которой находятся собственные
числа корреляционной матрицы,
корреляционной матрицы, - матрица, столбцы которой – собственные
вектора корреляционной матрицы
- матрица, столбцы которой – собственные
вектора корреляционной матрицы .
Так как матрица R положительно определена,
т.е. ее главные миноры положительны, то
все собственные значения
.
Так как матрица R положительно определена,
т.е. ее главные миноры положительны, то
все собственные значения для любых
для любых .
.
Собственные
значения
 находятся как корни характеристического
уравнения
находятся как корни характеристического
уравнения

Собственный
вектор
 ,
соответствующий собственному значению
,
соответствующий собственному значению корреляционной матрицы
корреляционной матрицы ,
определяется как отличное от нуля
решение уравнения
,
определяется как отличное от нуля
решение уравнения

Нормированный
собственный вектор
 равен
равен

Превращение
в нуль недиагональных членов означает,
что признаки становятся независимыми
друг от друга ( при
при ).
).
Суммарная
дисперсия всей системы
 переменных в выборочной совокупности
остается прежней. Однако её значения
перераспределяется. Процедура нахождения
значений этих дисперсий представляет
собой нахождение собственных значений
переменных в выборочной совокупности
остается прежней. Однако её значения
перераспределяется. Процедура нахождения
значений этих дисперсий представляет
собой нахождение собственных значений корреляционной матрицы для каждого из
корреляционной матрицы для каждого из -признаков.
Сумма этих собственных значений
-признаков.
Сумма этих собственных значений равна следу корреляционной матрицы,
т.е.
равна следу корреляционной матрицы,
т.е. ,
то есть количеству переменных. Эти
собственные значения и есть величины
дисперсии признаков
,
то есть количеству переменных. Эти
собственные значения и есть величины
дисперсии признаков в условиях, если бы признаки были бы
независимыми друг от друга.
в условиях, если бы признаки были бы
независимыми друг от друга.
В
методе главных компонент сначала по
исходным данным рассчитывается
корреляционная матрица. Затем производят
её ортогональное преобразование и
посредством этого находят факторные
нагрузки
 для всех
для всех переменных и
переменных и факторов (матрицу факторных нагрузок),
собственные значения
факторов (матрицу факторных нагрузок),
собственные значения и определяют веса факторов.
и определяют веса факторов.
Матрицу
факторных нагрузок А можно определить
как
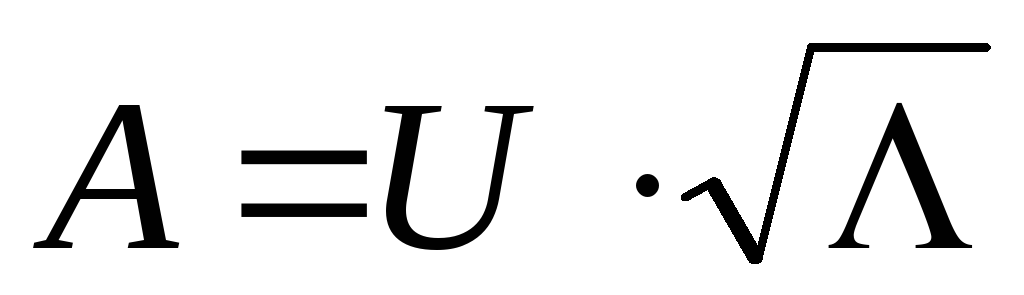 ,
а
,
а -й
столбец матрицы А - как
-й
столбец матрицы А - как .
.
Вес
факторов
 или
или отражает долю в общей дисперсии, вносимую
данным фактором.
отражает долю в общей дисперсии, вносимую
данным фактором.
Факторные
нагрузки изменяются от –1 до +1 и являются
аналогом коэффициентов корреляции. В
матрице факторных нагрузок необходимо
выделить значимые и незначимые нагрузки
с помощью критерия Стьюдента
 .
.
Сумма
квадратов нагрузок
 -го
фактора во всех
-го
фактора во всех -признаках
равна собственному значению данного
фактора
-признаках
равна собственному значению данного
фактора .
Тогда
.
Тогда -вклад
i-ой переменной в % в формировании j-го
фактора.
-вклад
i-ой переменной в % в формировании j-го
фактора.
Сумма
квадратов всех факторных нагрузок по
строке равна единице, полной дисперсии
одной переменной, а всех факторов по
всем переменным равна суммарной дисперсии
(т.е. следу или порядку корреляционной
матрицы, или сумме её собственных
значений)
 .
.
В
общем виде факторная структура i–го
признака представляется в форме
 ,
в которую включаются лишь значимые
нагрузки. Используя матрицу факторных
нагрузок можно вычислить значения всех
факторов для каждого наблюдения исходной
выборочной совокупности по формуле:
,
в которую включаются лишь значимые
нагрузки. Используя матрицу факторных
нагрузок можно вычислить значения всех
факторов для каждого наблюдения исходной
выборочной совокупности по формуле:
 ,
,
где
 – значение j-ого фактора у t-ого
наблюдения,
– значение j-ого фактора у t-ого
наблюдения, -стандартизированное
значение i–ого признака у t-ого наблюдения
исходной выборки;
-стандартизированное
значение i–ого признака у t-ого наблюдения
исходной выборки; –факторная нагрузка,
–факторная нагрузка, –собственное значение, отвечающее
фактору j. Эти вычисленные значения
–собственное значение, отвечающее
фактору j. Эти вычисленные значения широко используются для графического
представления результатов факторного
анализа.
широко используются для графического
представления результатов факторного
анализа.
По
матрице факторных нагрузок может быть
восстановлена корреляционная матрица:
 .
.
Часть дисперсии переменной, объясняемая главными компонентами, называется общностью
 ,
,
где
 - номер переменной, а
- номер переменной, а -номер главной компоненты. Восстановленные
только по главным компонентам коэффициенты
корреляции будут меньше исходных по
абсолютной величине, а на диагонали
будут не 1, а величины общностей.
-номер главной компоненты. Восстановленные
только по главным компонентам коэффициенты
корреляции будут меньше исходных по
абсолютной величине, а на диагонали
будут не 1, а величины общностей.
Удельный
вклад
 -й
главной компоненты определяется по
формуле
-й
главной компоненты определяется по
формуле
 .
.
Суммарный
вклад учитываемых
 главных компонент определяется из
выражения
главных компонент определяется из
выражения
 .
.
Обычно
для анализа используют
 первых главных компонент, вклад которых
в суммарную дисперсию превышает 60-70%.
первых главных компонент, вклад которых
в суммарную дисперсию превышает 60-70%.
Матрица факторных нагрузок А используется для интерпретации главных компонент, при этом обычно рассматриваются те значения, которые превышают 0,5.
Значения главных компонент задаются матрицей

Главные компоненты
5.1 Методы множественной регрессии и канонической корреляции предполагают разбиение имеющегося набора признаков на две части. Однако, далеко не всегда такое разбиение может быть объективно хорошо обоснованным, в связи с чем возникает необходимость в таких подходах к анализу взаимосвязей показателей, которые предполагали бы рассмотрение вектора признаков как единого целого. Разумеется, при реализации подобных подходов в этой батарее признаков может быть обнаружена определенная неоднородность, когда объективно выявятся несколько групп переменных. Для признаков из одной такой группы взаимные корреляции будут гораздо выше по сравнению с сочетаниями показателей из разных групп. Однако, эта группировка будет опираться на результаты объективного анализа данных, а - не на априорные произвольные соображения исследователя.
5.2 При изучении корреляционных связей внутри некоторого единого набора m признаков
X "= X 1 X 2 X 3 ... X m
можно воспользоваться тем же самым способом, который применялся в множественном регрессионном анализе и методе канонических корреляций - получением новых переменных, вариация которых полно отражает существование многомерных корреляций.
Целью рассмотрения внутригрупповых связей единого набора признаков является определение и наглядное представление объективно существующих основных направлений соотносительной вариации этих переменных. Поэтому, для этих целей можно ввести некие новые переменные Y i , находимые как линейные комбинации исходного набора признаков X
Y 1 = b 1 "X = b 11 X 1 + b 12 X 2 + b 13 X 3 + ... + b 1m X m
Y 2 = b 2 "X = b 21 X 1 + b 22 X 2 + b 23 X 3 + ... + b 2m X m
Y 3 = b 3 "X = b 31 X 1 + b 32 X 2 + b 33 X 3 + ... + b 3m X m (5.1)
... ... ... ... ... ... ...
Y m = b m "X = b m1 X 1 + b m2 X 2 + b m3 X 3 + ... + b m m X m
и обладающие рядом желательных свойств. Пусть для определенности число новых признаков равно числу исходных показателей (m).
Одним из таких желательных оптимальных свойств может быть взаимная некор-релированность новых переменных, то есть диагональный вид их ковариационной матрицы
S y1 2 0 0 ... 0
0 s y2 2 0 ... 0
S y = 0 0 s y3 2 ... 0 , (5.2)
... ... ... ... ...
0 0 0 … s ym 2
где s yi 2 - дисперсия i-го нового признака Y i . Некоррелированность новых переменных кроме своего очевидного удобства имеет важное свойство - каждый новый признак Y i будет учитывать только свою независимую часть информации об изменчивости и коррелированности исходных показателей X.
Вторым необходимым свойством новых признаков является упорядоченный учет вариации исходных показателей. Так, пусть первая новая переменная Y 1 будет учитывать максимальную долю суммарной вариации признаков X. Это, как мы позже увидим, равносильно требованию того, чтобы Y 1 имела бы максимально возможную дисперсию s y1 2 . С учетом равенства (1.17) это условие может быть записано в виде
s y1 2 = b 1 "Sb 1 = max , (5.3)
где S - ковариационная матрица исходных признаков X, b 1 - вектор, включающий коэффициенты b 11 , b 12 , b 13 , ..., b 1m при помощи которых, по значениям X 1 , X 2 , X 3 , ..., X m можно получить значение Y 1 .
Пусть вторая новая переменная Y 2 описывает максимальную часть того компонента суммарной вариации, который остался после учета наибольшей его доли в изменчивости первого нового признака Y 1 . Для достижения этого необходимо выполнение условия
s y2 2 = b 2 "Sb 2 = max , (5.4)
при нулевой связи Y 1 с Y 2 , (т.е. r y1y2 = 0) и при s y1 2 > s y2 2 .
Аналогичным образом, третий новый признак Y 3 должен описывать третью по степени важности часть вариации исходных признаков, для чего его дисперсия должна быть также максимальной
s y3 2 = b 3 "Sb 3 = max , (5.5)
при условиях, что Y 3 нескоррелирован с первыми двумя новыми признаками Y 1 и Y 2 (т.е. r y1y3 = 0, r y2y3 = 0) и s y1 2 > s y2 > s y3 2 .
Таким образом, для дисперсий всех новых переменных характерна упорядоченность по величине
s y1 2 > s y2 2 > s y3 2 > ... > s y m 2 . (5.6)
5.3 Векторы из формулы (5.1) b 1 , b 2 , b 3 , ..., b m , при помощи которых должен осу-ществляться переход к новым переменным Y i , могут быть записаны в виде матрицы
B = b 1 b 2 b 3 ... b m . (5.7)
Переход от набора исходных признаков X к набору новых переменных Y может быть представлен в виде матричной формулы
Y = B" X , (5.8)
а получение ковариационной матрицы новых признаков и достижение условия (5.2) некоррелированности новых переменных в соответствии с формулой (1.19) может быть представлено в виде
B"SB = S y , (5.9)
где ковариационная матрица новых переменных S y в силу их некоррелированности имеет диагональную форму. Из теории матриц (раздел А.25 Приложения А) известно, что, полу-чив для некоторой симметрической матрицы A собственные векторы u i и числа l i и обра-
зовав из них матрицы U и L , можно в соответствии с формулой (А.31) получить результат
U"AU = L ,
где L - диагональная матрица, включающая собственные числа симметрической матрицы A . Нетрудно видеть, что последнее равенство полностью совпадает с формулой (5.9). Поэтому, можно сделать следующий вывод. Желательные свойства новых переменных Y можно обеспечить, если векторы b 1 , b 2 , b 3 , ..., b m , при помощи которых должен осуществляться переход к этим переменным, будут собственными векторами ковариационной матрицы исходных признаков S . Тогда дисперсии новых признаков s yi 2 окажутся собственными числами
s y1 2 = l 1 , s y2 2 = l 2 , s y3 2 = l 3 , ... , s ym 2 = l m (5.10)
Новые переменные, переход к которым по формулам (5.1) и (5.8) осуществляется при помощи собственных векторов ковариационной матрицы исходных признаков, называются главными компонентами. В связи с тем, что число собственных векторов ковариационной матрицы в общем случае равно m - числу исходных признаков для этой матрицы, количество главных компонент также равно m.
В соответствии с теорией матриц для нахождения собственных чисел и векторов ковариационной матрицы следует решить уравнение
(S - l i I )b i = 0 . (5.11)
Это уравнение имеет решение, если выполняется условие равенства нулю определителя
½S - l i I ½ = 0 . (5.12)
Это условие по существу также оказывается уравнением, корнями которого являются все собственные числа l 1 , l 2 , l 3 , ..., l m ковариационной матрицы одновременно совпадающие с дисперсиями главных компонент. После получения этих чисел, для каждого i-го из них по уравнению (5.11) можно получить соответствующий собственный вектор b i . На практике для вычисления собственных чисел и векторов используются специальные итерационные процедуры (Приложение В).
Все собственные векторы можно записать в виде матрицы B , которая будет ортонормированной матрицей, так что (раздел А.24 Приложения А) для нее выполняется
B"B = BB" = I . (5.13)
Последнее означает, что для любой пары собственных векторов справедливо b i "b j = 0, а для любого такого вектора соблюдается равенство b i "b i = 1.
5.4 Проиллюстрируем получение главных компонент для простейшего случая двух исходных признаков X 1 и X 2 . Ковариационная матрица для этого набора равна
где s 1 и s 2 - средние квадратические отклонения признаков X 1 и X 2 , а r - коэффициент корреляции между ними. Тогда условие (5.12) можно записать в виде
S 1 2 - l i rs 1 s 2
rs 1 s 2 s 2 2 - l i

Рисунок 5.1 .Геометрический смысл главных компонент
Раскрывая определитель, можно получить уравнение
l 2 - l(s 1 2 + s 2 2) + s 1 2 s 2 2 (1 - r 2) = 0 ,
решая которое, можно получить два корня l 1 и l 2 . Уравнение (5.11) может быть также записано в виде
s 1 2 - l i r s 1 s 2 b i1 = 0
r s 1 s 2 s 2 2 - l i b i2 0
Подставляя в это уравнение l 1 , получим линейную систему
(s 1 2 - l 1) b 11 + rs 1 s 2 b 12 = 0
rs 1 s 2 b 11 + (s 2 2 - l 1)b 12 = 0 ,
решением которой являются элементы первого собственного вектора b 11 и b 12 . После аналогичной подстановки второго корня l 2 найдем элементы второго собственного вектора b 21 и b 22 .
5.5 Выясним геометрический смысл главных компонент. Наглядно это можно сделать лишь для простейшего случая двух признаков X 1 и X 2 . Пусть для них характерно двумерное нормальное распределение с положительным значением коэффициента корреляции. Если все индивидуальные наблюдения нанести на плоскость, образованную осями признаков, то соответствующие им точки расположатся внутри некоторого корреляционного эллипса (рис.5.1). Новые признаки Y 1 и Y 2 также могут быть изображены на этой же плоскости в виде новых осей. По смыслу метода для первой главной компоненты Y 1 , учитывающей максимально возможную суммарную дисперсию признаков X 1 и X 2 , должен достигаться максимум ее дисперсии. Это означает, что для Y 1 следует найти та-
кую ось, чтобы ширина распределения ее значений была бы наибольшей. Очевидно, что это будет достигаться, если эта ось совпадет по направлению с наибольшей осью корреляционного эллипса. Действительно, если мы спроецируем все соответствующие индивидуальным наблюдениям точки на эту координату, то получим нормальное распределение с максимально возможным размахом и наибольшей дисперсией. Это будет распределение индивидуальных значений первой главной компоненты Y 1 .
Ось, соответствующая второй главной компоненте Y 2 , должна быть проведена перпендикулярно к первой оси, так как это следует из условия некоррелированности главных компонент. Действительно, в этом случае мы получим новую систему координат с осями Y 1 и Y 2 , совпадающими по направлению с осями корреляционного эллипса. Можно видеть, что корреляционный эллипс при его рассмотрении в новой системе координат демонстрирует некоррелированность индивидуальных значений Y 1 и Y 2 , тогда как для величин исходных признаков X 1 и X 2 корреляция наблюдалась.
Переход от осей, связанных с исходными признаками X 1 и X 2 , к новой системе координат, ориентированной на главные компоненты Y 1 и Y 2 , равносилен повороту старых осей на некоторый угол j. Его величина может быть найдена по формуле
Tg 2j = . (5.14)
Переход от значений признаков X 1 и X 2 к главным компонентам может быть осуществлен в соответствии с результатами аналитической геометрии в виде
Y 1 = X 1 cos j + X 2 sin j
Y 2 = - X 1 sin j + X 2 cos j .
Этот же результат можно записать в матричном виде
Y 1 = cos j sin j X 1 и Y 2 = -sin j cos j X 1 ,
который точно соответствует преобразованию Y 1 = b 1 "X и Y 2 = b 2 "X . Иными словами,
= B" . (5.15)
Таким образом, матрица собственных векторов может также трактоваться как включающая тригонометрические функции угла поворота, который следует осуществить для перехода от системы координат, связанной с исходными признаками, к новым осям, опирающимся на главные компоненты.
Если мы имеем m исходных признаков X 1 , X 2 , X 3 , ..., X m , то наблюдения, состав-ляющие рассматриваемую выборку, расположатся внутри некоторого m-мерного корреляционного эллипсоида. Тогда ось первой главной компоненты совпадет по направлению с наибольшей осью этого эллипсоида, ось второй главной компоненты - со второй осью этого эллипсоида и т.д. Переход от первоначальной системы координат, связанной с осями признаков X 1 , X 2 , X 3 , ..., X m к новым осям главных компонент окажется равносильным осуществлению нескольких поворотов старых осей на углы j 1 , j 2 , j 3 , ..., а матрица перехода B от набора X к системе главных компонент Y , состоящая из собственных век-
торов ковариационной матрицы, включает в себя тригонометрические функции углов новых координатных осей со старыми осями исходных признаков.
5.6 В соответствии со свойствами собственных чисел и векторов следы ковариа-ционных матриц исходных признаков и главных компонент - равны. Иными словами
tr S = tr S y = tr L (5.16)
s 11 + s 22 + ... + s mm = l 1 + l 2 + ... + l m ,
т.е. сумма собственных чисел ковариационной матрицы равна сумме дисперсий всех исходных признаков. Поэтому, можно говорить о некоторой суммарной величине дисперсии исходных признаков равной tr S , и учитываемой системой собственных чисел.
То обстоятельство, что первая главная компонента имеет максимальную дисперсию, равную l 1 , автоматически означает, что она описывает и максимальную долю суммарной вариации исходных признаков tr S . Аналогично, вторая главная компонента имеет вторую по величине дисперсию l 2 , что соответствует второй по величине учитываемой доле суммарной вариации исходных признаков и т.д.
Для каждой главной компоненты можно определить долю суммарной величины изменчивости исходных признаков, которую она описывает
5.7 Очевидно, представление о суммарной вариации набора исходных признаков X 1 , X 2 , X 3 , ..., X m , измеряемой величиной tr S , имеет смысл только в том случае, когда все эти признаки измерены в одинаковых единицах. В противном случае придется складывать дисперсии, разных признаков, одни из которых будут выражены в квадратах миллиметров, другие - в квадратах килограммов, третьи – в квадратах радиан или градусов и т.д. Этого затруднения легко избежать, если от именованных значений признаков X ij перейти к их нормированным величинам z ij = (X ij - M i)./ S i где M i и S i - средняя арифметическая величина и среднее квадратическое отклонение i-го признака. Нормированные признаки z имеют нулевые средние, единичные дисперсии и не связаны с какими-либо единицами измерения. Ковариационная матрица исходных признаков S превратится в корреляционную матрицу R .
Все сказанное о главных компонентах, находимых для ковариационной матрицы, остается справедливым и для матрицы R . Здесь точно также можно, опираясь на собственные векторы корреляционной матрицы b 1 , b 2 , b 3 , ..., b m , перейти от исходных признаков z i к главным компонентам y 1 , y 2 , y 3 , ..., y m
y 1 = b 1 "z
y 2 = b 2 "z
y 3 = b 3 "z
y m = b m "z .
Это преобразование можно также записать в компактном виде
y = B"z ,

Рисунок 5.2 . Геометрический смысл главных компонент для двух нормированных признаков z 1 и z 2
где y - вектор значений главных компонент, B - матрица, включающая собственные векторы, z - вектор исходных нормированных признаков. Справедливым оказывается и равенство
B"RB = ... ... … , (5.18)
где l 1 , l 2 , l 3 , ..., l m - собственные числа корреляционной матрицы.
Результаты, получающиеся при анализе корреляционной матрицы, отличаются от аналогичных результатов для матрицы ковариационной. Во-первых, теперь можно рассматривать признаки, измеренные в разных единицах. Во-вторых, собственные векторы и числа, найденные для матриц R и S , также различны. В-третьих, главные компоненты, определенные по корреляционной матрице и опирающиеся на нормированные значения признаков z, оказываются центрироваными - т.е. имеющими нулевые средние величины.
К сожалению, определив собственные векторы и числа для корреляционной матрицы, перейти от них к аналогичным векторами и числам ковариационной матрицы - невозможно. На практике обычно используются главные компоненты, опирающиеся на корреляционную матрицу, как более универсальные.
5.8 Рассмотрим геометрический смысл главных компонент, определенных по корреляционной матрице. Наглядным здесь оказывается случай двух признаков z 1 и z 2 . Система координат, связанная с этими нормированными признаками, имеет нулевую точку, размещенную в центре графика (рис.5.2). Центральная точка корреляционного эллипса,
включающего все индивидуальные наблюдения, совпадет с центром системы координат. Очевидно, что ось первой главной компоненты, имеющая максимальную вариацию, совпадет с наибольшей осью корреляционного эллипса, а координата второй главной компоненты будет сориентирована по второй оси этого эллипса.
Переход от системы координат, связанной с исходными признаками z 1 и z 2 к новым осям главных компонент равносилен повороту первых осей на некоторый угол j. Дисперсии нормированных признаков равны 1 и по формуле (5.14) можно найти величину угла поворота j равную 45 o . Тогда матрица собственных векторов, которую можно определить через тригонометрические функции этого угла по формуле (5.15), будет равна
Cos j sin j 1 1 1
B " = = .
Sin j cos j (2) 1/2 -1 1
Значения собственных чисел для двумерного случая также несложно найти. Условие (5.12) окажется вида
что соответствует уравнению
l 2 - 2l + 1 - r 2 = 0 ,
которое имеет два корня
l 1 = 1 + r (5.19)
Таким образом, главные компоненты корреляционной матрицы для двух нормированных признаков могут быть найдены по очень простым формулам
Y 1 = (z 1 + z 2) (5.20)
Y 2 = (z 1 - z 2)
Их средние арифметические величины равны нулю, а средние квадратические отклонения имеют значения
s y1 = (l 1) 1/2 = (1 + r) 1/2
s y2 = (l 2) 1/2 = (1 - r) 1/2
5.9 В соответствии со свойствами собственных чисел и векторов следы корреляционной матрицы исходных признаков и матрицы собственных чисел - равны. Суммарная вариация m нормированных признаков равна m. Иными словами
tr R = m = tr L (5.21)
l 1 + l 2 + l 3 + ... + l m = m .
Тогда доля суммарной вариации исходных признаков, описываемая i-ой главной компонентой равна
Можно также ввести понятие P cn - доли суммарной вариации исходных признаков, описываемой первыми n главными компонентами,
n l 1 + l 2 + ... + l n
P cn = S P i = . (5.23)
То обстоятельство, что для собственных чисел наблюдается упорядоченность вида l 1 > l 2 > > l 3 > ... > l m , означает, что аналогичные соотношения будут свойственны и долям, описываемой главными компонентами вариации
P 1 > P 2 > P 3 > ... > P m . (5.24)
Свойство (5.24) влечет за собой специфический вид зависимости накопленной доли P сn от n (рис.5.3). В данном случае первые три главные компоненты описывают основную часть изменчивости признаков. Это означает, что часто немногие первые главные компоненты могут совместно учитывать до 80 - 90% суммарной вариации признаков, тогда как каждая последующая главная компонента будет увеличивать эту долю весьма незначительно. Тогда для дальнейшего рассмотрения и интерпретации можно использовать только эти немногие первые главные компоненты с уверенностью, что именно они описывают наиболее важные закономерности внутригрупповой изменчивости и коррелированности

Рисунок 5.3. Зависимость доли суммарной вариации признаков P cn , описываемой n первыми главными компонентами, от величины n. Число признаков m = 9

Рисунок 5.4. К определению конструкции критерия отсеивания главных компонент
признаков. Благодаря этому, число информативных новых переменных, с которыми следует работать, может быть уменьшено в 2 - 3 раза. Таким образом, главные компоненты имеют еще одно важное и полезное свойство - они значительно упрощают описание вариации исходных признаков и делают его более компактным. Такое уменьшение числа переменных всегда желательно, но оно связано с некоторыми искажениями взаимного расположения точек, соответствующих отдельным наблюдениям, в пространстве немногих первых главных компонент по сравнению с m-мерным пространством исходных признаков. Эти искажения возникают из-за попытки втиснуть пространство признаков в пространство первых главных компонент. Однако, в математической статистике доказывается, что из всех методов, позволяющих значительно уменьшить число переменных, переход к главным компонентам приводит к наименьшим искажениям структуры наблюдений связанных с этим уменьшением.
5.10 Важным вопросом анализа главных компонент является проблема определения их количества для дальнейшего рассмотрения. Очевидно, что увеличение числа главных компонент повышает накопленную долю учитываемой изменчивости P cn и приближает ее к 1. Одновременно, компактность получаемого описания уменьшается. Выбор того количества главных компонент, которое одновременно обеспечивает и полноту и компактность описания может базироваться на разных критериях, применяемых на практике. Перечислим наиболее распространенные из них.
Первый критерий основан на том соображении, что количество учитываемых главных компонент должно обеспечивать достаточную информативную полноту описания. Иными словами, рассматриваемые главные компоненты должны описывать большую часть суммарной изменчивости исходных признаков: до 75 - 90%. Выбор конкретного уровня накопленной доли P cn остается субъективным и зависящим как от мнения исследователя, так и от решаемой задачи.
Другой аналогичный критерий (критерий Кайзера) позволяет включать в рассмотрение главные компоненты с собственными числами большими 1. Он основан на том соображении, что 1 - это дисперсия одного нормированного исходного признака. Поэто-
му, включение в дальнейшее рассмотрение всех главных компонент с собственными числами большими 1 означает что мы рассматриваем только те новые переменные, которые имеют дисперсии не меньше чем у одного исходного признака. Критерий Кайзера весьма распространен и его использование заложено во многие пакеты программ статистической обработки данных, когда требуется задать минимальную величину учитываемого собственного числа, и по умолчанию часто принимается значение равное 1.
Несколько лучше теоретически обоснован критерий отсеивания Кеттела. Его применение основано на рассмотрении графика, на котором нанесены значения всех собственных чисел в порядке их убывания (рис.5.4). Критерий Кеттела основан на том эффекте, что нанесенная на график последовательность величин полученных собственных чисел обычно дает вогнутую линию. Несколько первых собственных чисел обнаруживают непрямолинейное уменьшение своего уровня. Однако, начиная с некоторого собственного числа, уменьшение этого уровня становится примерно прямолинейным и довольно пологим. Включение главных компонент в рассмотрение завершается той из них, собственное число которой начинает прямолинейный пологий участок графика. Так, на рисунке 5.4 в соответствие с критерием Кеттела в рассмотрение следует включить только первые три главные компоненты, потому что третье собственное число находится в самом начале прямолинейного пологого участка графика.
Критерий Кеттела основан на следующем. Если рассматривать данные по m признакам, искусственно полученные из таблицы нормально распределенных случайных чисел, то для них корреляции между признаками будут носить совершенно случайный характер и будут близкими к 0. При нахождении здесь главных компонент можно будет обнаружить постепенное уменьшение величины их собственных чисел, имеющее прямолинейной характер. Иными словами, прямолинейное уменьшение собственных чисел может свидетельствовать об отсутствии в соответствующей им информации о коррелированности признаков неслучайных связей.
5.11 При интерпретации главных компонент чаще всего используются собственные векторы, представленные в виде так называемых нагрузок - коэффициентов корреляции исходных признаков с главными компонентами. Собственные векторы b i , удовлетворяющие равенству (5.18), получаются в нормированном виде, так что b i "b i = 1. Это означает, что сумма квадратов элементов каждого собственного вектора равна 1. Собственные векторы, элементы которых являются нагрузками, могут быть легко найдены по формуле
a i = (l i) 1/2 b i . (5.25)
Иными словами, домножением нормированной формы собственного вектора на корень квадратный его собственного числа, можно получить набор нагрузок исходных признаков на соответствующую главную компоненту. Для векторов нагрузок справедливым оказывается равенство a i "a i = l i , означающее, что сумма квадратов нагрузок на i-ю главную компоненту равна i-му собственному числу. Компьютерные программы обычно выводят собственные векторы именно в виде нагрузок. При необходимости получения этих векторов в нормированном виде b i это можно сделать по простой формуле b i = a i / (l i) 1/2 .
5.12 Математические свойства собственных чисел и векторов таковы, что в соответствии с разделом А.25 Приложения А исходная корреляционная матрица R может быть представлена в виде R = BLB" , что также можно записать как
R = l 1 b 1 b 1 " + l 2 b 2 b 2 " + l 3 b 3 b 3 " + ... + l m b m b m " . (5.26)
Следует заметить, что любой из членов l i b i b i " , соответствующий i-й главной компоненте, является квадратной матрицей
L i b i1 2 l i b i1 b i2 l i b i1 b i3 … l i b i1 b im
l i b i b i " = l i b i1 b i2 l i b i2 2 l i b i2 b i3 ... l i b i2 b im . (5.27)
... ... ... ... ...
l i b i1 b im l i b i2 b im l i b i3 b im ... l i b im 2
Здесь b ij - элемент i-го собственного вектора у j-го исходного признака. Любой диагональный член такой матрицы l i b ij 2 есть некоторая доля вариации j-го признака, описываемая i-й главной компонентой. Тогда дисперсия любого j-го признака может быть представлена в виде
1 = l 1 b 1j 2 + l 2 b 2j 2 + l 3 b 3j 2 + ... + l m b mj 2 , (5.28)
означающем ее разложение по вкладам, зависящим от всех главных компонент.
Аналогично, любой внедиагональный член l i b ij b ik матрицы (5.27) является некоторой частью коэффициента корреляции r jk j-го и k-го признаков, учитываемой i-й главной компонентой. Тогда можно выписать разложение этого коэффициента в виде суммы
r jk = l 1 b 1j b 1k + l 2 b 2j b 2k + ... + l m b mj b mk , (5.29)
вкладов в него всех m главных компонент.
Таким образом, из формул (5.28) и (5.29) можно наглядно видеть, что каждая главная компонента описывает определенную часть дисперсии каждого исходного признака и коэффициента корреляции каждого их сочетания.
С учетом, того, что элементы нормированной формы собственных векторов b ij связаны с нагрузками a ij простым соотношением (5.25), разложение (5.26) может быть выписано и через собственные векторы нагрузок R = AA" , что также можно представить как
R = a 1 a 1 " + a 2 a 2 " + a 3 a 3 " + ... + a m a m " , (5.30)
т.е. как сумму вкладов каждой из m главных компонент. Каждый из этих вкладов a i a i " можно записать в виде матрицы
A i1 2 a i1 a i2 a i1 a i3 ... a i1 a im
a i1 a i2 a i2 2 a i2 a i3 ... a i2 a im
a i a i " = a i1 a i3 a i2 a i3 a i3 2 ... a i3 a im , (5.31)
... ... ... ... ...
a i1 a im a i2 a im a i3 a im ... a im 2
на диагоналях которой размещены a ij 2 - вклады в дисперсию j-го исходного признака, а внедиагональные элементы a ij a ik - есть аналогичные вклады в коэффициент корреляции r jk j-го и k-го признаков.
Метод главных компонент
Метод главных компонент (англ. Principal component analysis, PCA ) - один из основных способов уменьшить размерность данных, потеряв наименьшее количество информации . Изобретен К. Пирсоном (англ. Karl Pearson ) в г. Применяется во многих областях, таких как распознавание образов , компьютерное зрение , сжатие данных и т. п. Вычисление главных компонент сводится к вычислению собственных векторов и собственных значений ковариационной матрицы исходных данных. Иногда метод главных компонент называют преобразованием Кархунена-Лоэва (англ. Karhunen-Loeve ) или преобразованием Хотеллинга (англ. Hotelling transform ). Другие способы уменьшения размерности данных - это метод независимых компонент, многомерное шкалирование, а также многочисленные нелинейные обобщения: метод главных кривых и многообразий, метод упругих карт , поиск наилучшей проекции (англ. Projection Pursuit ), нейросетевые методы «узкого горла », и др.
Формальная постановка задачи
Задача анализа главных компонент, имеет, как минимум, четыре базовых версии:
- аппроксимировать данные линейными многообразиями меньшей размерности;
- найти подпространства меньшей размерности, в ортогональной проекции на которые разброс данных (то есть среднеквадратичное отклонение от среднего значения) максимален;
- найти подпространства меньшей размерности, в ортогональной проекции на которые среднеквадратичное расстояние между точками максимально;
- для данной многомерной случайной величины построить такое ортогональное преобразование координат, что в результате корреляции между отдельными координатами обратятся в ноль.
Первые три версии оперируют конечными множествами данных. Они эквивалентны и не используют никакой гипотезы о статистическом порождении данных. Четвёртая версия оперирует случайными величинами. Конечные множества появляются здесь как выборки из данного распределения, а решение трёх первых задач - как приближение к «истинному» преобразованию Кархунена-Лоэва. При этом возникает дополнительный и не вполне тривиальный вопрос о точности этого приближения.
Аппроксимация данных линейными многообразиями
Иллюстрация к знаменитой работе К. Пирсона (1901): даны точки на плоскости, - расстояние от до прямой . Ищется прямая , минимизирующая сумму
Метод главных компонент начинался с задачи наилучшей аппроксимации конечного множества точек прямыми и плоскостями (К. Пирсон, 1901). Дано конечное множество векторов . Для каждого среди всех -мерных линейных многообразий в найти такое , что сумма квадратов уклонений от минимальна:
,где - евклидово расстояние от точки до линейного многообразия. Всякое -мерное линейное многообразие в может быть задано как множество линейных комбинаций , где параметры пробегают вещественную прямую , а - ортонормированный набор векторов
,где евклидова норма, - евклидово скалярное произведение, или в координатной форме:
.Решение задачи аппроксимации для даётся набором вложенных линейных многообразий , . Эти линейные многообразия определяются ортонормированным набором векторов (векторами главных компонент) и вектором . Вектор ищется, как решение задачи минимизации для :
.Векторы главных компонент могут быть найдены как решения однотипных задач оптимизации :
1) централизуем данные (вычитаем среднее): . Теперь ; 2) находим первую главную компоненту как решение задачи; . Если решение не единственно, то выбираем одно из них. 3) Вычитаем из данных проекцию на первую главную компоненту: ; 4) находим вторую главную компоненту как решение задачи . Если решение не единственно, то выбираем одно из них. … 2k-1) Вычитаем проекцию на -ю главную компоненту (напомним, что проекции на предшествующие главные компоненты уже вычтены): ; 2k) находим k-ю главную компоненту как решение задачи: . Если решение не единственно, то выбираем одно из них. …
На каждом подготовительном шаге вычитаем проекцию на предшествующую главную компоненту. Найденные векторы ортонормированы просто в результате решения описанной задачи оптимизации, однако чтобы не дать ошибкам вычисления нарушить взаимную ортогональность векторов главных компонент, можно включать в условия задачи оптимизации.
Неединственность в определении помимо тривиального произвола в выборе знака ( и решают ту же задачу) может быть более существенной и происходить, например, из условий симметрии данных. Последняя главная компонента - единичный вектор, ортогональный всем предыдущим .
Поиск ортогональных проекций с наибольшим рассеянием

Первая главная компонента максимизирует выборочную дисперсию проекции данных
Пусть нам дан центрированный набор векторов данных (среднее арифметическое значение равно нулю). Задача - найти такое ортогональное преобразование в новую систему координат , для которого были бы верны следующие условия:
Теория сингулярного разложения была создана Дж. Дж. Сильвестром (англ. James Joseph Sylvester ) в г. и изложена во всех подробных руководствах по теории матриц .
Простой итерационный алгоритм сингулярного разложения
Основная процедура - поиск наилучшего приближения произвольной матрицы матрицей вида (где - -мерный вектор, а - -мерный вектор) методом наименьших квадратов:
Решение этой задачи дается последовательными итерациями по явным формулам. При фиксированном векторе значения , доставляющие минимум форме , однозначно и явно определяются из равенств :
Аналогично, при фиксированном векторе определяются значения :
B качестве начального приближения вектора возьмем случайный вектор единичной длины, вычисляем вектор , далее для этого вектора вычисляем вектор и т. д. Каждый шаг уменьшает значение . В качестве критерия остановки используется малость относительного уменьшения значения минимизируемого функционала за шаг итерации () или малость самого значения .
В результате для матрицы получили наилучшее приближение матрицей вида (здесь верхним индексом обозначен номер приближения). Далее, из матрицы вычитаем полученную матрицу , и для полученной матрицы уклонений вновь ищем наилучшее приближение этого же вида и т. д., пока, например, норма не станет достаточно малой. В результате получили итерационную процедуру разложения матрицы в виде суммы матриц ранга 1, то есть . Полагаем и нормируем векторы : В результате получена аппроксимация сингулярных чисел и сингулярных векторов (правых - и левых - ).
К достоинствам этого алгоритма относится его исключительная простота и возможность почти без изменений перенести его на данные с пробелами , а также взвешенные данные.
Существуют различные модификации базового алгоритма, улучшающие точность и устойчивость. Например, векторы главных компонент при разных должны быть ортогональны «по построению», однако при большом числе итерации (большая размерность, много компонент) малые отклонения от ортогональности накапливаются и может потребоваться специальная коррекция на каждом шаге, обеспечивающая его ортогональность ранее найденным главным компонентам.
Сингулярное разложение тензоров и тензорный метод главных компонент
Часто вектор данных имеет дополнительную структуру прямоугольной таблицы (например, плоское изображение) или даже многомерной таблицы - то есть тензора : , . В этом случае также эффективно применять сингулярное разложение. Определение, основные формулы и алгоритмы переносятся практически без изменений: вместо матрицы данных имеем -индексную величину , где первый индекс -номер точки (тензора) данных.
Основная процедура - поиск наилучшего приближения тензора тензором вида (где - -мерный вектор ( - число точек данных), - вектор размерности при ) методом наименьших квадратов:
Решение этой задачи дается последовательными итерациями по явным формулам. Если заданы все векторы-сомножители кроме одного , то этот оставшийся определяется явно из достаточных условий минимума.
B качестве начального приближения векторов () возьмем случайные векторы единичной длины, вычислим вектор , далее для этого вектора и данных векторов вычисляем вектор и т. д. (циклически перебирая индексы) Каждый шаг уменьшает значение . Алгоритм, очевидно, сходится. В качестве критерия остановки используется малость относительного уменьшения значения минимизируемого функционала за цикл или малость самого значения . Далее, из тензора вычитаем полученное приближение и для остатка вновь ищем наилучшее приближение этого же вида и т. д., пока, например, норма очередного остатка не станет достаточно малой.
Это многокомпонентное сингулярное разложение (тензорный метод главных компонент) успешно применяется при обработке изображений, видеосигналов, и, шире, любых данных, имеющих табличную или тензорную структуру.
Матрица преобразования к главным компонентам
Матрица преобразования данных к главным компонентам состоит из векторов главных компонент, расположенных в порядке убывания собственных значений:
( означает транспонирование),То есть, матрица является ортогональной .
Большая часть вариации данных будет сосредоточена в первых координатах, что позволяет перейти к пространству меньшей размерности.
Остаточная дисперсия
Пусть данные центрированы, . При замене векторов данных на их проекцию на первые главных компонент вносится средний квадрат ошибки в расчете на один вектор данных:
где собственные значения эмпирической ковариационной матрицы , расположенные в порядке убывания, с учетом кратности.
Эта величина называется остаточной дисперсией . Величина
называется объяснённой дисперсией . Их сумма равна выборочной дисперсии. Соответствующий квадрат относительной ошибки - это отношение остаточной дисперсии к выборочной дисперсии (то есть доля необъяснённой дисперсии ):
По относительной ошибке оценивается применимость метода главных компонент с проецированием на первые компонент.
Замечание : в большинстве вычислительных алгоритмов собственные числа с соответствующими собственными векторами - главными компонентами вычисляются в порядке «от больших - к меньшим». Для вычисления достаточно вычислить первые собственных чисел и след эмпирической ковариационной матрицы , (сумму диагональных элементов , то есть дисперсий по осям). Тогда
Отбор главных компонент по правилу Кайзера
Целевой подход к оценке числа главных компонент по необходимой доле объяснённой дисперсии формально применим всегда, однако неявно он предполагает, что нет разделения на «сигнал» и «шум», и любая заранее заданная точность имеет смысл. Поэтому часто более продуктивна иная эвристика, основывающаяся на гипотезе о наличии «сигнала» (сравнительно малая размерность, относительно большая амплитуда) и «шума» (большая размерность, относительно малая амплитуда). С этой точки зрения метод главных компонент работает как фильтр: сигнал содержится, в основном, в проекции на первые главные компоненты, а в остальных компонентах пропорция шума намного выше.
Вопрос: как оценить число необходимых главных компонент, если отношение «сигнал/шум» заранее неизвестно?
Простейший и старейший метод отбора главных компонент даёт правило Кайзера (англ. Kaiser"s rule ): значимы те главные компоненты, для которых
то есть превосходит среднее значение (среднюю выборочную дисперсию координат вектора данных). Правило Кайзера хорошо работает в простых случаях, когда есть несколько главных компонент с , намного превосходящими среднее значение, а остальные собственные числа меньше него. В более сложных случаях оно может давать слишком много значимых главных компонент. Если данные нормированы на единичную выборочную дисперсию по осям, то правило Кайзера приобретает особо простой вид: значимы только те главные компоненты, для которых
Оценка числа главных компонент по правилу сломанной трости

Пример: оценка числа главных компонент по правилу сломанной трости в размерности 5.
Одним из наиболее популярных эвристических подходов к оценке числа необходимых главных компонент является правило сломанной трости (англ. Broken stick model ) . Набор нормированных на единичную сумму собственных чисел (, ) сравнивается с распределением длин обломков трости единичной длины, сломанной в -й случайно выбранной точке (точки разлома выбираются независимо и равнораспределены по длине трости). Пусть () - длины полученных кусков трости, занумерованные в порядке убывания длины: . Нетрудно найти математическое ожидание :
По правилу сломанной трости -й собственный вектор (в порядке убывания собственных чисел ) сохраняется в списке главных компонент, если
На Рис. приведён пример для 5-мерного случая:
=(1+1/2+1/3+1/4+1/5)/5; =(1/2+1/3+1/4+1/5)/5; =(1/3+1/4+1/5)/5; =(1/4+1/5)/5; =(1/5)/5.Для примера выбрано
=0.5; =0.3; =0.1; =0.06; =0.04.По правилу сломанной трости в этом примере следует оставлять 2 главных компоненты:
По оценкам пользователей, правило сломанной трости имеет тенденцию занижать количество значимых главных компонент.
Нормировка
Нормировка после приведения к главным компонентам
После проецирования на первые главных компонент с удобно произвести нормировку на единичную (выборочную) дисперсию по осям. Дисперсия вдоль й главной компоненты равна ), поэтому для нормировки надо разделить соответствующую координату на . Это преобразование не является ортогональным и не сохраняет скалярного произведения. Ковариационная матрица проекции данных после нормировки становится единичной, проекции на любые два ортогональных направления становятся независимыми величинами, а любой ортонормированный базис становится базисом главных компонент (напомним, что нормировка меняет отношение ортогональности векторов). Отображение из пространства исходных данных на первые главных компонент вместе с нормировкой задается матрицей
.Именно это преобразование чаще всего называется преобразованием Кархунена-Лоэва. Здесь - векторы-столбцы, а верхний индекс означает транспонирование.
Нормировка до вычисления главных компонент
Предупреждение : не следует путать нормировку, проводимую после преобразования к главным компонентам, с нормировкой и «обезразмериванием» при предобработке данных , проводимой до вычисления главных компонент. Предварительная нормировка нужна для обоснованного выбора метрики, в которой будет вычисляться наилучшая аппроксимация данных, или будут искаться направления наибольшего разброса (что эквивалентно). Например, если данные представляют собой трёхмерные векторы из «метров, литров и килограмм», то при использовании стандартного евклидового расстояния разница в 1 метр по первой координате будет вносить тот же вклад, что разница в 1 литр по второй, или в 1 кг по третьей. Обычно системы единиц, в которых представлены исходные данные, недостаточно точно отображают наши представления о естественных масштабах по осям, и проводится «обезразмеривание»: каждая координата делится на некоторый масштаб, определяемый данными, целями их обработки и процессами измерения и сбора данных.
Есть три cущественно различных стандартных подхода к такой нормировке: на единичную дисперсию по осям (масштабы по осям равны средним квадратичным уклонениям - после этого преобразования ковариационная матрица совпадает с матрицей коэффициентов корреляции), на равную точность измерения (масштаб по оси пропорционален точности измерения данной величины) и на равные требования в задаче (масштаб по оси определяется требуемой точностью прогноза данной величины или допустимым её искажением - уровнем толерантности). На выбор предобработки влияют содержательная постановка задачи, а также условия сбора данных (например, если коллекция данных принципиально не завершена и данные будут ещё поступать, то нерационально выбирать нормировку строго на единичную дисперсию, даже если это соответствует смыслу задачи, поскольку это предполагает перенормировку всех данных после получения новой порции; разумнее выбрать некоторый масштаб, грубо оценивающий стандартное отклонение, и далее его не менять).
Предварительная нормировка на единичную дисперсию по осям разрушается поворотом системы координат, если оси не являются главными компонентами, и нормировка при предобработке данных не заменяет нормировку после приведения к главным компонентам.
Механическая аналогия и метод главных компонент для взвешенных данных
Если сопоставить каждому вектору данных единичную массу, то эмпирическая ковариационная матрица совпадёт с тензором инерции этой системы точечных масс (делённым на полную массу ), а задача о главных компонентых - с задачей приведения тензора инерции к главным осям. Можно использовать дополнительную свободу в выборе значений масс для учета важности точек данных или надежности их значений (важным данным или данным из более надежных источников приписываются бо́льшие массы). Если вектору данных придаётся масса , то вместо эмпирической ковариационной матрицы получим
Все дальнейшие операции по приведению к главным компонентам производятся так же, как и в основной версии метода: ищем ортонормированный собственный базис , упорядочиваем его по убыванию собственных значений, оцениваем средневзвешенную ошибку аппроксимации данных первыми компонентами (по суммам собственных чисел ), нормируем и т. п.
Более общий способ взвешивания даёт максимизация взвешенной суммы попарных расстояний между проекциями. Для каждых двух точек данных, вводится вес ; и . Вместо эмпирической ковариационной матрицы используется
При симметричная матрица положительно определена, поскольку положительна квадратичная форма:
Далее ищем ортонормированный собственный базис , упорядочиваем его по убыванию собственных значений, оцениваем средневзвешенную ошибку аппроксимации данных первыми компонентами и т. д. - в точности так же, как и в основном алгоритме.
Этот способ применяется при наличии классов : для из разных классов вес вес выбирается бо́льшим, чем для точек одного класса. В результате, в проекции на взвешенные главные компоненты различные классы «раздвигаются» на большее расстояние.
Другое применение - снижение влияния больших уклонений (оутлайеров, англ. Outlier ), которые могут искажать картину из-за использования среднеквадратичного расстояния: если выбрать , то влияние больших уклонений будет уменьшено. Таким образом, описанная модификация метода главных компонент является более робастной , чем классическая.
Специальная терминология
В статистике при использовании метода главных компонент используют несколько специальных терминов.
Матрица данных ; каждая строка - вектор предобработанных данных (центрированных и правильно нормированных ), число строк - (количество векторов данных), число столбцов - (размерность пространства данных);
Матрица нагрузок (Loadings) ; каждый столбец - вектор главных компонент, число строк - (размерность пространства данных), число столбцов - (количество векторов главных компонент, выбранных для проецирования);
Матрица счетов (Scores) ; каждая строка - проекция вектора данных на главных компонент; число строк - (количество векторов данных), число столбцов - (количество векторов главных компонент, выбранных для проецирования);
Матрица Z-счетов (Z-scores) ; каждая строка - проекция вектора данных на главных компонент, нормированная на единичную выборочную дисперсию; число строк - (количество векторов данных), число столбцов - (количество векторов главных компонент, выбранных для проецирования);
Матрица ошибок (или остатков ) (Errors or residuals) .
Основная формула:
Пределы применимости и ограничения эффективности метода
Метод главных компонент применим всегда. Распространённое утверждение о том, что он применим только к нормально распределённым данным (или для распределений, близких к нормальным) неверно: в исходной формулировке К. Пирсона ставится задача об аппроксимации конечного множества данных и отсутствует даже гипотеза о их статистическом порождении, не говоря уж о распределении.
Однако метод не всегда эффективно снижает размерность при заданных ограничениях на точность . Прямые и плоскости не всегда обеспечивают хорошую аппроксимацию. Например, данные могут с хорошей точностью следовать какой-нибудь кривой, а эта кривая может быть сложно расположена в пространстве данных. В этом случае метод главных компонент для приемлемой точности потребует нескольких компонент (вместо одной), или вообще не даст снижения размерности при приемлемой точности. Для работы с такими «кривыми» главными компонентами изобретен метод главных многообразий и различные версии нелинейного метода главных компонент . Больше неприятностей могут доставить данные сложной топологии. Для их аппроксимации также изобретены различные методы, например самоорганизующиеся карты Кохонена , нейронный газ или топологические грамматики . Если данные статистически порождены с распределением, сильно отличающимся от нормального, то для аппроксимации распределения полезно перейти от главных компонент к независимым компонентам , которые уже не ортогональны в исходном скалярном произведении. Наконец, для изотропного распределения (даже нормального) вместо эллипсоида рассеяния получаем шар, и уменьшить размерность методами аппроксимации невозможно.
Примеры использования
Визуализация данных
Визуализация данных - представление в наглядной форме данных эксперимента или результатов теоретического исследования.
Первым выбором в визуализации множества данных является ортогональное проецирование на плоскость первых двух главных компонент (или 3-мерное пространство первых трёх главных компонент). Плоскость проектирования является, по сути плоским двумерным «экраном», расположенным таким образом, чтобы обеспечить «картинку» данных с наименьшими искажениями. Такая проекция будет оптимальна (среди всех ортогональных проекций на разные двумерные экраны) в трех отношениях:
- Минимальна сумма квадратов расстояний от точек данных до проекций на плоскость первых главных компонент, то есть экран расположен максимально близко по отношению к облаку точек.
- Минимальна сумма искажений квадратов расстояний между всеми парами точек из облака данных после проецирования точек на плоскость.
- Минимальна сумма искажений квадратов расстояний между всеми точками данных и их «центром тяжести».
Визуализация данных является одним из наиболее широко используемых приложений метода главных компонент и его нелинейных обобщений .
Компрессия изображений и видео
Для уменьшения пространственной избыточности пикселей при кодировании изображений и видео используется линейные преобразования блоков пикселей. Последующие квантования полученных коэффициентов и кодирование без потерь позволяют получить значительные коэффициенты сжатия. Использование преобразования PCA в качестве линейного преобразования является для некоторых типов данных оптимальным с точки зрения размера полученных данных при одинаковом искажении . На данный момент этот метод активно не используется, в основном из-за большой вычислительной сложности. Также сжатия данных можно достичь отбрасывая последние коэффициенты преобразования.
Подавление шума на изображениях
Хемометрика
Метод главных компонент - один из основных методов в хемометрике (англ. Chemometrics ). Позволяет разделить матрицу исходных данных X на две части: «содержательную» и «шум». По наиболее популярному определению «Хемометрика - это химическая дисциплина, применяющая математические, статистические и другие методы, основанные на формальной логике, для построения или отбора оптимальных методов измерения и планов эксперимента, а также для извлечения наиболее важной информации при анализе экспериментальных данных».
Психодиагностика
- анализ данных (описание результатов опросов или других исследований, представленных в виде массивов числовых данных);
- описание социальных явлений (построение моделей явлений, в том числе и математических моделей).
В политологии метод главных компонент был основным инструментом проекта «Политический Атлас Современности» для линейного и нелинейного анализа рейтингов 192 стран мира по пяти специально разработанным интегральным индексам (уровня жизни, международного влияния, угроз, государственности и демократии). Для картографии результатов этого анализа разработана специальная ГИС (Геоинформационная система), объединяющая географическое пространство с пространством признаков. Также созданы карты данных политического атласа , использующие в качестве подложки двумерные главные многообразия в пятимерном пространстве стран. Отличие карты данных от географической карты заключается в том, что на географической карте рядом оказываются объекты, которые имеют сходные географические координаты, в то время как на карте данных рядом оказываются объекты (страны) с похожими признаками (индексами).
Метод главных компонентов (английский - principal component analysis, PCA) упрощает сложность высокоразмерных данных, сохраняя тенденции и шаблоны. Он делает это, преобразуя данные в меньшие размеры, которые действуют, как резюме функций. Такие данные очень распространены в разных отраслях науки и техники, и возникают, когда для каждого образца измеряются несколько признаков, например, таких как экспрессия многих видов. Подобный тип данных представляет проблемы, вызванные повышенной частотой ошибок из-за множественной коррекции данных.
Метод похож на кластеризацию - находит шаблоны без ссылок и анализирует их, проверяя, взяты ли образцы из разных групп исследования, и имеют ли они существенные различия. Как и во всех статистических методах, его можно применить неправильно. Масштабирование переменных может привести к разным результатам анализа, и очень важно, чтобы оно не корректировалось, на предмет соответствия предыдущему значению данных.
Цели анализа компонентов
Основная цель метода - обнаружить и уменьшить размерность набора данных, определить новые значимые базовые переменные. Для этого предлагается использовать специальные инструменты, например, собрать многомерные данные в матрице данных TableOfReal, в которой строки связаны со случаями и столбцами переменных. Поэтому TableOfReal интерпретируется как векторы данных numberOfRows, каждый вектор которых имеет число элементов Columns.
Традиционно метод главных компонентов выполняется по ковариационной матрице или по корреляционной матрице, которые можно вычислить из матрицы данных. Ковариационная матрица содержит масштабированные суммы квадратов и кросс-произведений. Корреляционная матрица подобна ковариационной матрице, но в ней сначала переменные, то есть столбцы, были стандартизованы. Вначале придется стандартизировать данные, если дисперсии или единицы измерения переменных сильно отличаются. Чтобы выполнить анализ, выбирают матрицу данных TabelOfReal в списке объектов и даже нажимают перейти.
Это приведет к появлению нового объекта в списке объектов по методу главных компонент. Теперь можно составить график кривых собственных значений, чтобы получить представление о важности каждого. И также программа может предложить действие: получить долю дисперсии или проверить равенство числа собственных значений и получить их равенство. Поскольку компоненты получены путем решения конкретной задачи оптимизации, у них есть некоторые «встроенные» свойства, например, максимальная изменчивость. Кроме того, существует ряд других их свойств, которые могут обеспечить факторный анализ:
- дисперсию каждого, при этом доля полной дисперсии исходных переменных задается собственными значениями;
- вычисления оценки, которые иллюстрируют значение каждого компонента при наблюдении;
- получение нагрузок, которые описывают корреляцию между каждым компонентом и каждой переменной;
- корреляцию между исходными переменными, воспроизведенными с помощью р-компонента;
- воспроизведения исходных данных могут быть воспроизведены с р-компонентов;
- «поворот» компонентов, чтобы повысить их интерпретируемость.
Выбор количества точек хранения
Существует два способа выбрать необходимое количество компонентов для хранения. Оба метода основаны на отношениях между собственными значениями. Для этого рекомендуется построить график значений. Если точки на графике имеют тенденцию выравниваться и достаточно близки к нулю, то их можно игнорировать. Ограничивают количество компонентов до числа, на которое приходится определенная доля общей дисперсии. Например, если пользователя удовлетворяет 95% от общей дисперсии - получают количество компонентов (VAF) 0.95.
Основные компоненты получают проектированием многомерного статистического анализа метода главных компонентов datavectors на пространстве собственных векторов. Это можно сделать двумя способами - непосредственно из TableOfReal без предварительного формирования PCA объекта и затем можно отобразить конфигурацию или ее номера. Выбрать объект и TableOfReal вместе и «Конфигурация», таким образом, выполняется анализ в собственном окружении компонентов.
Если стартовая точка оказывается симметричной матрицей, например, ковариационной, сначала выполняют сокращение до формы, а затем алгоритм QL с неявными сдвигами. Если же наоборот и отправная точка является матрица данных, то нельзя формировать матрицу с суммами квадратов. Вместо этого, переходят от численно более стабильного способа, и образуют разложения по сингулярным значениям. Тогда матрица будет содержать собственные векторы, а квадратные диагональные элементы - собственные значения.
Основным компонентом является нормализованная линейная комбинация исходных предикторов в наборе данных по методу главных компонент для чайников. На изображении выше PC1 и PC2 являются основными компонентами. Допустим, есть ряд предикторов, как X1, X2...,Xp.
Основной компонент можно записать в виде: Z1 = 11X1 + 21X2 + 31X3 + .... + p1Xp
- Z1 - является первым главным компонентом;
- p1 - является вектором нагрузки, состоящим из нагрузок (1, 2.) первого основного компонента.
Нагрузки ограничены суммой квадрата равного 1. Это связано с тем, что большая величина нагрузок может привести к большой дисперсии. Он также определяет направление основной компоненты (Z1), по которой данные больше всего различаются. Это приводит к тому, что линия в пространстве р-мер, ближе всего к n-наблюдениям.
Близость измеряется с использованием среднеквадратичного евклидова расстояния. X1..Xp являются нормированными предикторами. Нормализованные предикторы имеют среднее значение, равное нулю, а стандартное отклонение равно единице. Следовательно, первый главный компонент - это линейная комбинация исходных предикторных переменных, которая фиксирует максимальную дисперсию в наборе данных. Он определяет направление наибольшей изменчивости в данных. Чем больше изменчивость, зафиксированная в первом компоненте, тем больше информация, полученная им. Ни один другой не может иметь изменчивость выше первого основного.
Первый основной компонент приводит к строке, которая ближе всего к данным и сводит к минимуму сумму квадрата расстояния между точкой данных и линией. Второй главный компонент (Z2) также представляет собой линейную комбинацию исходных предикторов, которая фиксирует оставшуюся дисперсию в наборе данных и некоррелирована Z1. Другими словами, корреляция между первым и вторым компонентами должна равняться нулю. Он может быть представлен как: Z2 = 12X1 + 22X2 + 32X3 + .... + p2Xp.
Если они некоррелированы, их направления должны быть ортогональными.
После того как вычислены главные компоненты начинают процесс прогнозирования тестовых данных с их использованием. Процесс метода главных компонент для чайников прост.

Например, необходимо сделать преобразование в тестовый набор, включая функцию центра и масштабирования в языке R (вер.3.4.2) и его библиотеке rvest. R - свободный язык программирования для статистических вычислений и графики. Он был реконструирован в 1992 году для решения статистических задач пользователями. Это полный процесс моделирования после извлечения PCA.

Для реализации PCA в python импортируют данные из библиотеки sklearn. Интерпретация остается такой же, как и пользователей R. Только набор данных, используемый для Python, представляет собой очищенную версию, в которой отсутствуют вмененные недостающие значения, а категориальные переменные преобразуются в числовые. Процесс моделирования остается таким же, как описано выше для пользователей R. Метод главных компонент, пример расчета:

Идея метода основного компонента заключается в приближении этого выражения для выполнения факторного анализа. Вместо суммирования от 1 до p теперь суммируются от 1 до m, игнорируя последние p-m членов в сумме и получая третье выражение. Можно переписать это, как показано в выражении, которое используется для определения матрицы факторных нагрузок L, что дает окончательное выражение в матричной нотации. Если используются стандартизованные измерения, заменяют S на матрицу корреляционной выборки R.

Это формирует матрицу L фактор-нагрузки в факторном анализе и сопровождается транспонированной L. Для оценки конкретных дисперсий фактор-модель для матрицы дисперсии-ковариации.
Теперь будет равна матрице дисперсии-ковариации минус LL " .

- Xi - вектор наблюдений для i-го субъекта.
- S обозначает нашу выборочную дисперсионно-ковариационную матрицу.
Тогда p собственные значения для этой матрицы ковариации дисперсии, а также соответствующих собственных векторов для этой матрицы.
Собственные значения S:λ^1, λ^2, ... , λ^п.
Собственные векторы S:е^1, e^2, ... , e^п.

Анализ PCA - это мощный и популярный метод многомерного анализа, который позволяет исследовать многомерные наборы данных с количественными переменными. По этой методике широко используется метод главных компонент в биоинформатике, маркетинге, социологии и многих других областях. XLSTAT предоставляет полную и гибкую функцию для изучения данных непосредственно в Excel и предлагает несколько стандартных и расширенных опций, которые позволят получить глубокое представление о пользовательских данных.
Можно запустить программу на необработанных данных или на матрицах различий, добавить дополнительные переменные или наблюдения, отфильтровать переменные в соответствии с различными критериями для оптимизации чтения карт. Кроме того, можно выполнять повороты. Легко настраивать корреляционный круг, график наблюдений в качестве стандартных диаграмм Excel. Достаточно перенести данные из отчета о результатах, чтобы использовать их в анализе.
XLSTAT предлагает несколько методов обработки данных, которые будут использоваться на входных данных до вычислений основного компонента:
- Pearson, классический PCA, который автоматически стандартизирует данные для вычислений, чтобы избежать раздутого влияния переменных с большими отклонениями от результата.
- Ковариация, которая работает с нестандартными отклонениями.
- Полихорические, для порядковых данных.
Примеры анализа данных размерностей
Можно рассмотреть метод главных компонентов на примере выполнения симметричной корреляционной или ковариационной матрицы. Это означает, что матрица должна быть числовой и иметь стандартизованные данные. Допустим, есть набор данных размерностью 300 (n) × 50 (p). Где n - представляет количество наблюдений, а p - число предикторов.
Поскольку имеется большой p = 50, может быть p(p-1)/2 диаграмма рассеяния. В этом случае было бы хорошим подходом выбрать подмножество предиктора p (p<< 50), который фиксирует количество информации. Затем следует составление графика наблюдения в полученном низкоразмерном пространстве. Не следует забывать, что каждое измерение является линейной комбинацией р-функций.

Пример для матрицы с двумя переменными. В этом примере метода главных компонентов создается набор данных с двумя переменными (большая длина и диагональная длина) с использованием искусственных данных Дэвиса.
Компоненты можно нарисовать на диаграмме рассеяния следующим образом.

Этот график иллюстрирует идею первого или главного компонента, обеспечивающего оптимальную сводку данных - никакая другая линия, нарисованная на таком графике рассеяния, не создаст набор прогнозируемых значений точек данных на линии с меньшей дисперсией.
Первый компонент также имеет приложение в регрессии с уменьшенной главной осью (RMA), в которой предполагается, что как x-, так и y-переменные имеют ошибки или неопределенности или, где нет четкого различия между предсказателем и ответом.
Метод главных компонентов в эконометрике - это анализ переменных, таких как ВНП, инфляция, обменные курсы и т. д. Их уравнения затем оцениваются по имеющимся данным, главным образом совокупным временным рядам. Однако эконометрические модели могут использоваться для многих приложений, а не для макроэкономических. Таким образом, эконометрика означает экономическое измерение.
Применение статистических методов к соответствующей эконометрике данных показывает взаимосвязь между экономическими переменными. Простой пример эконометрической модели. Предполагается, что ежемесячные расходы потребителей линейно зависят от доходов потребителей в предыдущем месяце. Тогда модель будет состоять из уравнения

Задачей эконометрика является получение оценок параметров a и b. Эти оценочные значения параметров, если они используются в уравнении модели, позволяют прогнозировать будущие значения потребления, которые будут зависеть от дохода предыдущего месяца. При разработке этих видов моделей необходимо учитывать несколько моментов:
- характер вероятностного процесса, который генерирует данные;
- уровень знаний об этом;
- размер системы;
- форма анализа;
- горизонт прогноза;
- математическая сложность системы.
Все эти предпосылки важны, потому что от них зависят источники ошибок, вытекающих из модели. Кроме того, для решения этих проблем необходимо определить метод прогнозирования. Его можно привести к линейной модели, даже если имеется только небольшая выборка. Этот тип является одним из самых общих, для которого можно создать прогнозный анализ.
Непараметрическая статистика
Метод главных компонент для непараметрических данных относится к методам измерения, в которых данные извлекаются из определенного распределения. Непараметрические статистические методы широко используются в различных типах исследований. На практике, когда предположение о нормальности измерений не выполняется, параметрические статистические методы могут приводить к вводящим в заблуждение результатам. Напротив, непараметрические методы делают гораздо менее строгие предположения о распределении по измерениям.
Они являются достоверными независимо от лежащих в их основе распределений наблюдений. Из-за этого привлекательного преимущества для анализа различных типов экспериментальных конструкций было разработано много разных типов непараметрических тестов. Такие проекты охватывают дизайн с одной выборкой, дизайн с двумя образцами, дизайн рандомизированных блоков. В настоящее время непараметрический байесовский подход с применением метода главных компонентов используется для упрощения анализа надежности железнодорожных систем.
Железнодорожная система представляет собой типичную крупномасштабную сложную систему с взаимосвязанными подсистемами, которые содержат многочисленные компоненты. Надежность системы сохраняется за счет соответствующих мер по техническому обслуживанию, а экономичное управление активами требует точной оценки надежности на самом низком уровне. Однако данные реальной надежности на уровне компонентов железнодорожной системы не всегда доступны на практике, не говоря уже о завершении. Распределение жизненных циклов компонентов от производителей часто скрывается и усложняется фактическим использованием и рабочей средой. Таким образом, анализ надежности требует подходящей методологии для оценки времени жизни компонента в условиях отсутствия данных об отказах.
Метод главных компонент в общественных науках используется для выполнения двух главных задач:
- анализа по данным социологических исследований;
- построения моделей общественных явлений.
Алгоритмы расчета моделей
Алгоритмы метода главных компонент дают другое представление о структуре модели и ее интерпретации. Они являются отражением того, как PCA используется в разных дисциплинах. Алгоритм нелинейного итеративного частичного наименьшего квадрата NIPALS представляет собой последовательный метод вычисления компонентов. Вычисление может быть прекращено досрочно, когда пользователь считает, что их достаточно. Большинство компьютерных пакетов имеют тенденцию использовать алгоритм NIPALS, поскольку он имеет два основных преимущества:
- он обрабатывает отсутствующие данные;
- последовательно вычисляет компоненты.
Цель рассмотрения этого алгоритма:
- дает дополнительное представление о том, что означают нагрузки и оценки;
- показывает, как каждый компонент не зависит ортогонально от других компонентов;
- показывает, как алгоритм может обрабатывать недостающие данные.
Алгоритм последовательно извлекает каждый компонент, начиная с первого направления наибольшей дисперсии, а затем второго и т. д. NIPALS вычисляет один компонент за раз. Вычисленный первый эквивалентен t1t1, а также p1p1 векторов, которые были бы найдены из собственного значения или разложения по сингулярным значениям, может обрабатывать недостающие данные в XX. Он всегда сходится, но сходимость иногда может быть медленной. И также известен, как алгоритм мощности для вычисления собственных векторов и собственных значений и отлично работает для очень больших наборов данных. Google использовал этот алгоритм для ранних версий своей поисковой системы.
Алгоритм NIPALS показан на фото ниже.

Оценки коэффициента матрицы Т затем вычисляется как T=XW и в частичной мере коэффициентов регрессии квадратов B из Y на X, вычисляются, как B = WQ. Альтернативный метод оценки для частей регрессии частичных наименьших квадратов можно описать следующим образом.

Метод главных компонентов - это инструмент для определения основных осей дисперсии в наборе данных и позволяет легко исследовать ключевые переменные данных. Правильно примененный метод является одним из самых мощных в наборе инструментов анализа данных.